REPL is dead, long live REPL
 Brandon Waselnuk·March 30, 2026
Brandon Waselnuk·March 30, 2026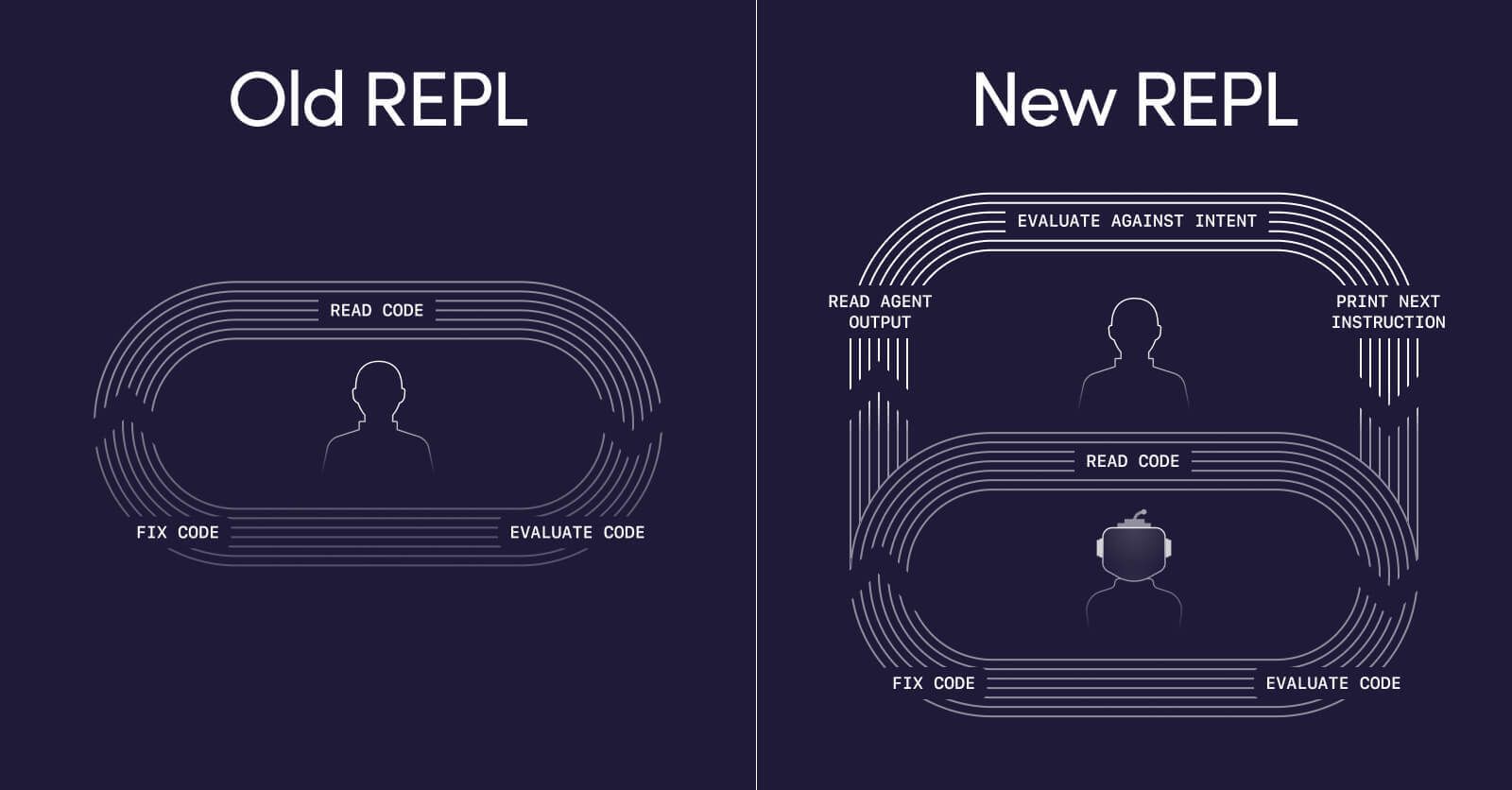
The Read-Eval-Print Loop is how programming works. Write code, run it, read the output, adjust. It's so fundamental it barely feels like a methodology.
And it still is how programming works. But the layer you're REPLing at is shifting.
Agentic coding tools (Claude Code, Codex, Cursor, Copilot agent mode, Windsurf) have gotten good enough that they can run the REPL loop themselves. They write code, execute it, read the errors, and iterate. Not perfectly. Not every time. But well enough that a growing number of engineering tasks no longer require you to be the one reading line-by-line output.
This doesn't mean REPL is dead. It means it's been promoted.
The old REPL#
For decades, REPL looked like this. You Read the error message, the stack trace, the unexpected output. You Eval what went wrong: a type mismatch, an off-by-one, a misunderstood API. You Print the next line of code, the fix, the next hypothesis. And you Loop, running it again.
This is the REPL at the syntax and runtime layer. You're in direct conversation with the machine. Your inputs are code. Your outputs are program behaviour. The feedback loop is tight, immediate, and personal. You're building a mental model of the system one iteration at a time.
The new REPL#
The engineers getting the most out of this moment have moved their REPL up one level of abstraction. You Read the code the agent produced: does it match your intent? Does the architecture hold? Are there edge cases it missed? You Eval whether the output moves you toward your goal. Whether it reflects how your team actually builds this part of the system, not only whether it compiles. Does this approach handle the auth edge case from last quarter's incident? Does it follow the data access pattern your team chose for a reason that isn't documented anywhere except a Slack thread? You Print your next instruction: clarify the intent, add a constraint, redirect the approach. And you Loop, letting the agent take another pass.
Same loop. Different inputs and outputs. Instead of reading stack traces, you're reading diffs. Instead of printing code, you're printing instructions.
REPL all the way up#
There's a fractal quality to this. The agent is REPLing at the code layer so you can REPL at the intent layer.
This isn't new. It's how abstraction has always worked in software. We stopped writing assembly so we could think in functions. We stopped managing memory so we could think in objects. Each time, the lower-level loop didn't disappear. It got absorbed by a layer beneath us.
The agentic shift is the same pattern, with one important caveat: previous abstraction layers were deterministic. When you moved from assembly to C, the compiler was reliable. Agents are probabilistic. They get things wrong, sometimes confidently. This means the "Eval" step in your higher-level REPL carries more weight than it did in past abstraction shifts. You can't just trust the output. You have to assess it. But the trend line is clear, and the engineers who learn to REPL at the intent layer now are getting ahead of it.
What this looks like in practice#
Here's where this stops being theoretical.
I recently ran an experiment at work: implementing the same feature twice with an agentic coding tool, using two different approaches. Full disclosure: I work at Unblocked, and the context-gathering tool I used in one of the runs is our product. I'm biased. But the principle holds regardless of tooling, and the results were stark enough to be worth sharing.
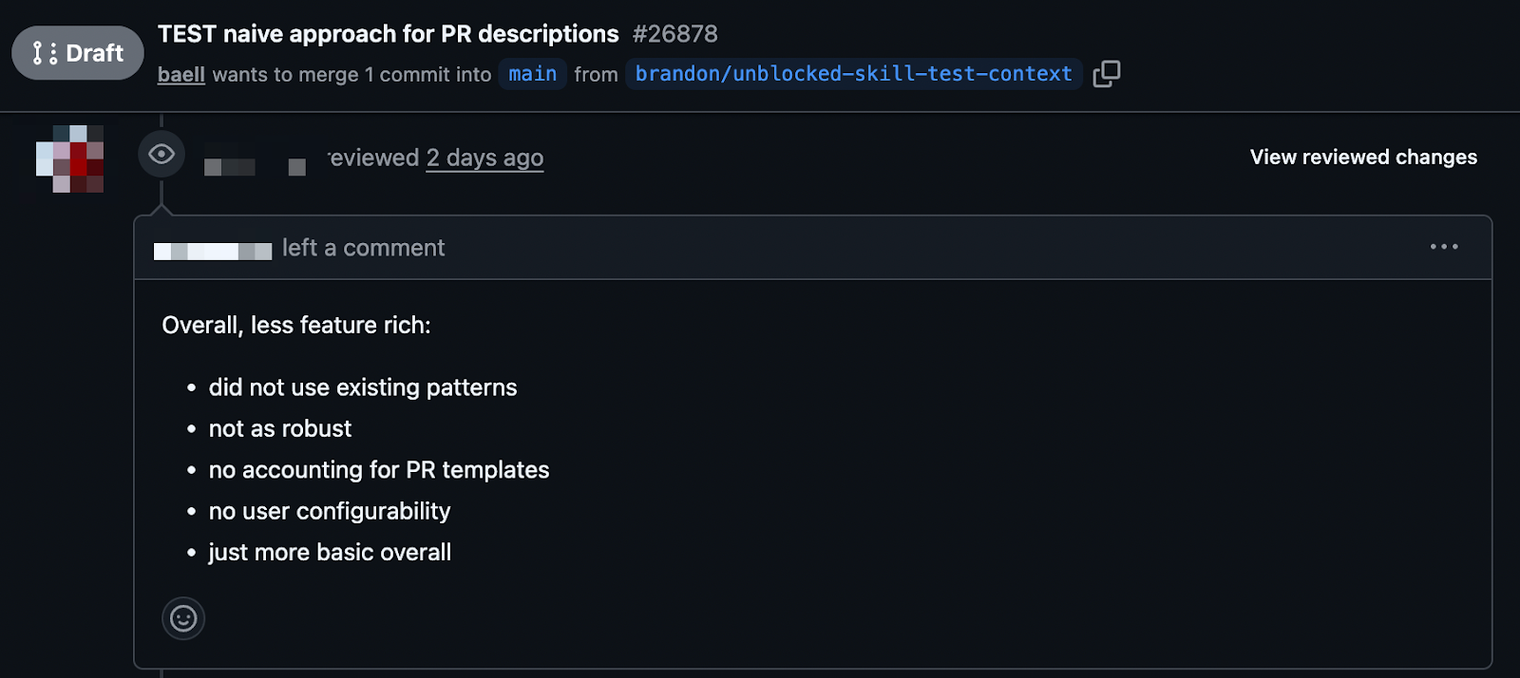
Run one: naive, code-level REPL. I gave the agent a prompt and let it generate code directly. It did what agents do. It read the codebase, made reasonable-looking guesses about patterns and conventions, and produced a PR. The result? Our most senior engineer took one look and wanted to close it. It got one thing right. The rest was, in his words, slop. The agent had been REPLing at the code level (reading files, evaluating syntax, printing code) but it had no understanding of the intent behind the codebase's patterns. It was looping fast and confidently in the wrong direction, burning through tokens and time on every wasted iteration.
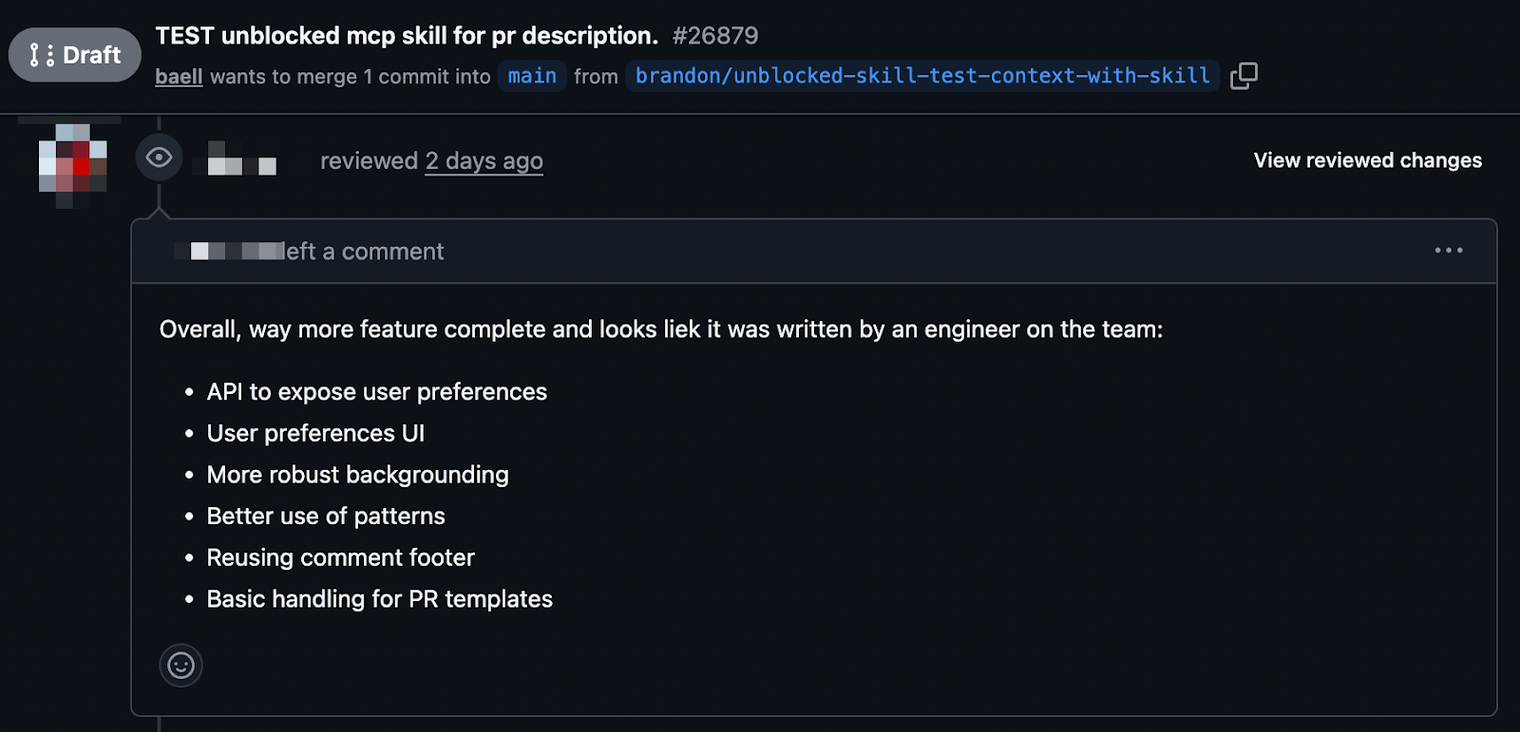
Run two: intent-level REPL. Same prompt. Same agent. But this time, before the planning stage, I used a skill that pulled seed context from Unblocked, gathering relevant knowledge from Slack conversations, Notion docs, the codebase itself, and existing PRs, both merged and some open. This is the part that matters: in a large codebase, critical knowledge is scattered. It lives in a PR comment explaining why a pattern was chosen, a Slack thread debating an architecture decision, a Notion doc that three people have read. The agent can't find this on its own, and if you try to feed it manually, you're burning time gathering context and tokens stuffing it into the conversation window. Unblocked's context engine serves exactly the right context, accurately and at low token counts, so the agent starts with a real understanding of intent instead of expensive guesswork. I reviewed the plan against additional context before letting the agent proceed to implementation.
The result was a drastically better PR. The same senior engineer liked it. The feedback was minor, the kind of normal review comments you'd expect on any solid contribution. Not a rewrite. Not slop. A real, mergeable PR.
Same agent. Same prompt. The difference was where I operated the loop. In the first run, I let the agent REPL at the code level on its own, and it wandered, each loop costing time and tokens with diminishing returns. In the second, I REPLed at the intent level: gathering context, reviewing the plan, assessing alignment before a single line of code was generated. Fewer loops, less token burn, and a better outcome. The lower-level REPL still happened. I just wasn't the one running it.
And this is the point worth landing on: gathering that context, curating it, reviewing the plan against it. That was the intent-level REPL in action. It looks like "just prompt engineering" if you squint, but you're actually running the Read-Eval-Print Loop on intent and architecture instead of syntax and stack traces. The skill isn't writing a better prompt. The skill is running a better loop.
Without Unblocked#
With Unblocked#
If you're already an Unblocked customer, you can set this up with a single command:
curl -fsSL https://getunblocked.com/install-mcp.sh | bash
What changes in practice#
When you shift your REPL to the intent layer, the work itself changes.
The biggest shift is in what you produce. Your output is no longer code. It's an instruction. Engineers who are precise about intent, constraints, and edge cases get correct code on the first or second loop, saving time and tokens on every iteration they don't need to run. The ones who are vague burn both watching agents wander. This is a learnable skill, but it's a different skill than writing code. It's closer to writing a good design doc than a good function.
The second shift is in what you consume. The difference between the two runs in my experiment wasn't the agent's capability. It was the context I fed into the loop. Relevant Slack threads, prior PRs, team conventions. Operating at the intent level means reading the full picture of how your team builds software, and making sure the agent can see it too. The engineers who treat context curation as a first-class part of their workflow will consistently outperform those who skip it.
The third shift is in what you evaluate. You're no longer checking whether code compiles. You're checking whether it's correct: whether it fits the architecture, follows team conventions, handles the edge cases you know about. This is where your years of experience pay off. And it's cognitively demanding, because you're reviewing code you didn't write, produced by something that doesn't share your mental model.
The upside is scope. When you're not spending your cognitive budget on the syntax-level REPL, you can hold more of the system in your head. You can plan across multiple components, think about integration points, and sequence work at a broader level than before.
Remember, it’s hard to do things differently#
Here's what this demands: you have to trust the agent enough to let go of the lower-level loop, while maintaining enough skill to catch when it gets things wrong.
That's a real tension. If you never operate at the code level, you lose the intuition that makes you a good reviewer. If you insist on always operating at the code level, you're leaving a lot on the table.
And there's a harder version of this question: if agents absorb the code-level REPL, how do junior engineers build the intuition they need to eventually operate the intent-level REPL well? That's a real problem without a clean answer yet. The engineers who grew up debugging stack traces have a foundation that can't be skipped, but the way that foundation gets built may need to change.
For now, the best engineers are fluent at both layers. They move between them depending on the task. Greenfield CRUD work? Stay at the intent layer. Debugging a subtle concurrency issue? Drop down to the code layer. But the balance is shifting. My experiment showed that the context and planning, the intent-level loop, was the difference between a PR that got closed and one that got merged. That's real, and it's increasingly where the work happens.
REPL isn't dead#
REPL is the same as it's ever been: the most natural way for a human to iterate toward a solution. What's changed is that there's now another entity capable of running it at the lower layer.
The engineers who thrive next won't be the ones who write the best code or craft the best prompts. They'll be the ones who run the best loops — who know what context to gather, when to review a plan, and when to let the agent run. Right now, most of us are still looping at the wrong layer.