Finally, everyone is talking about context
Developer tools promise "context-aware" AI, but more data access isn't context. The AI development stack needs a new infrastructure layer -- a context engine -- to turn information into understanding.


A context engine is the infrastructure layer that turns scattered organizational knowledge — code, PRs, tickets, Slack, and docs — into decision-grade context: the conflict-resolved understanding an AI agent needs to make a correct decision. Unlike retrieval (RAG), which fetches plausible chunks, a context engine synthesizes understanding, resolves conflicts, and ranks what’s relevant before the agent sees it. Access is not understanding.
If you pay attention to the developer tools ecosystem, you’ve probably noticed more messaging promising “context-aware” everything.
Many developer tool vendors now position “context” as the key to higher quality code and fewer back and forth loops with agents. For many of these tool providers, “context aware” means the tool can see more than a single file, with users manually supplying extra data through MCP, APIs, CLIs, projects, or rules.
But that isn’t context.

Context, by definition, implies understanding.
Expanding visibility or wiring in more tools only provides access. You connect an agent to Slack, Jira, GitHub, docs, or observability data, it can query those systems and return something that looks roughly correct. Then it stops. Discernment is left to the agent, and agents are not good at that.
Increasing access to information#
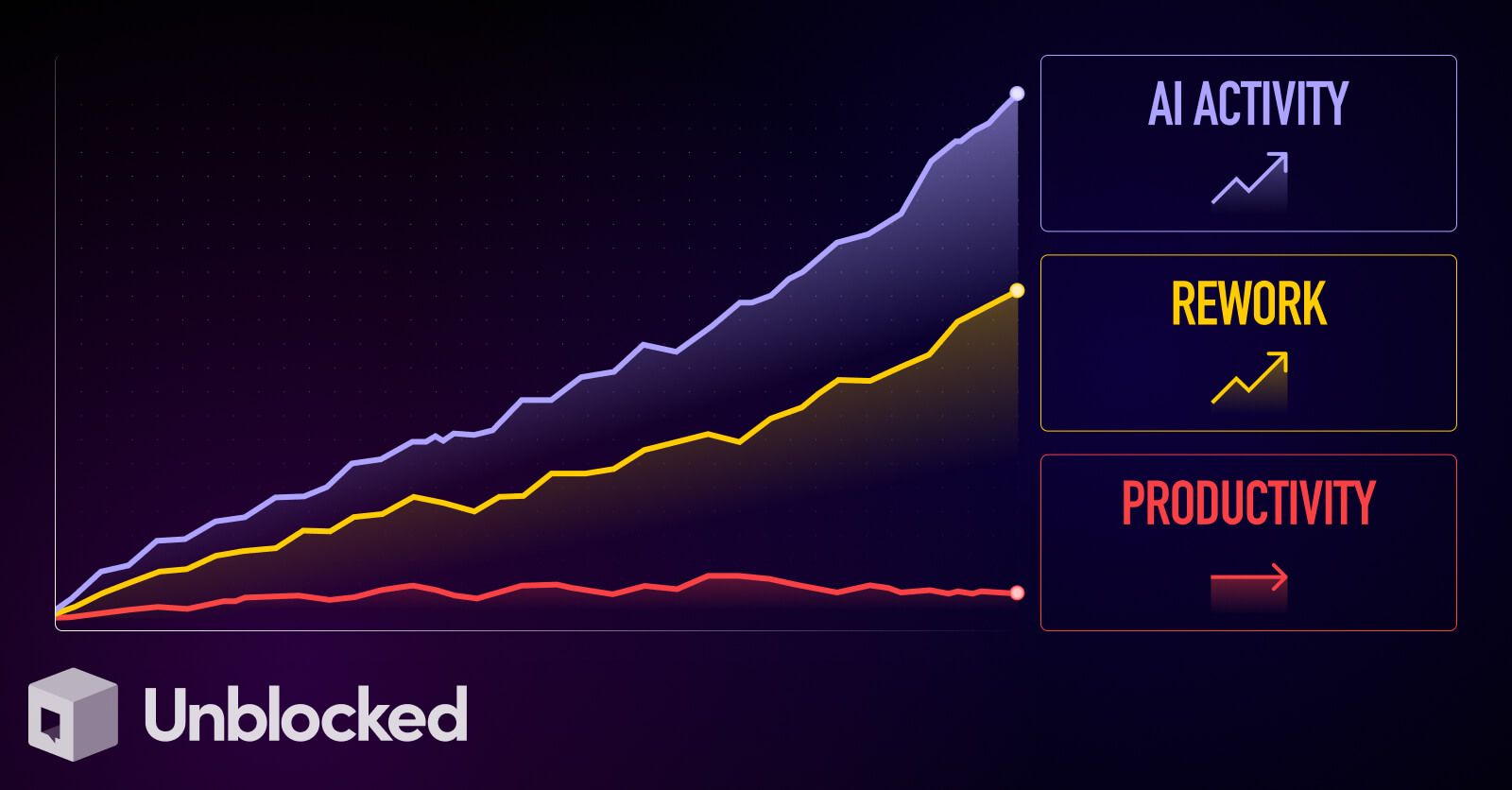
When ChatGPT and GitHub Copilot first appeared, they worked in a vacuum. They generated syntactically correct code that was often wrong in intent. The industry responded by expanding access: larger context windows, MCP, project knowledge, repo search, and cross-codebase awareness. Claude added Skills, GitHub Copilot added Spaces for organizational context, and Cursor made the codebase queryable. This helped, but it did not solve the problem developers actually have.
Information ≠ context#
Additional information has made code generation feel smoother, but not meaningfully better. Painfully, as you wire up countless MCP services to provide increased information, the problem worsens.
Agents struggle with a problem called “satisfaction of search”. They are optimized to produce an answer, not to fully understand the problem. Once they retrieve something that looks plausible, they stop. Their search behavior is shallow and confidence driven, shaped by training that rewards fluent completion rather than exhaustive exploration. Tool use reinforces this pattern: each query is treated as a cost, so the agent minimizes exploration and settles early.
Developers behave differently. They keep searching until the answer aligns with intent, constraints, and prior decisions. Agents lack that sense of decision-grade completeness. They cannot tell when context is missing, when a result is merely convenient, or when stopping early creates risk.
As a result, adding more data sources improves access to information, but it does not fix judgment.
| Capability | “Context-aware” tooling (access) | Context engine (understanding) |
|---|---|---|
| What it does | Connects more sources (MCP, repo search, larger windows) | Synthesizes sources into unified understanding |
| Conflicting sources | Surfaces both, leaves reconciliation to you | Resolves by recency, authority, and org patterns |
| Relevance | Returns what matches the query | Returns what’s decision-relevant for this developer, now |
| Permissions | Per-source, in isolation | Unified access control across all sources |
| Output | Fragments / information | Decision-grade context |
Innovative engineering teams see this gap clearly and are trying to close it. Hedgineer’s team built a company-wide knowledge layer using Claude Skills. Impressive but costly for a small team. LinkedIn built contextual agent playbooks giving AI deep organizational understanding. It’s inspiring work; the team is now focused on building more dynamism into the tool.
These teams are treating context as infrastructure. They’re building systems that continuously learn relationships between code, conversations, decisions, and documentation.
The missing layer in the AI development stack#
The gap between information access and actionable context points to a new infrastructure layer for AI development: a context engine.
Rather than acting as a thin retrieval or reasoning layer, a context engine continuously synthesizes organizational knowledge across disparate sources into unified, queryable understanding.
Its job is not to fetch more data, but to determine which context is decision relevant, for this developer, at this moment.
These are the essential pieces:
User relevance and Permissions#
Context must be scoped to the right developer and constrained by what they are allowed to see. Individual MCP servers handle authentication in isolation and have little notion of personalization. They may know who a user is, but not what that person is working on, who they collaborate with, or which decisions are relevant to their role. As a result, agents require manual scoping and still surface information that is either irrelevant or incomplete.
A context engine maintains unified access control across all data sources while modeling user relevance. It respects source system permissions, tracks short term task context and long term preferences, and focuses retrieval on what matters for this developer in this moment. The result is context that is both safe and useful, without requiring constant re specification.
Relationship-aware knowledge retrieval#
Organizational knowledge is scattered and interdependent. Code links to Jira tickets, which link to PRs, which reference Slack discussions and documentation. Agents connected to individual MCP servers search these systems sequentially. They query one source, get a plausible answer, and stop, with no understanding that critical context may live elsewhere.
A context engine queries all relevant sources in parallel, explores relationships between artifacts, and assembles a connected view of the problem space. It traverses these links in real time, building understanding across the entire knowledge graph rather than returning isolated fragments. This shifts retrieval from sequential hunting to comprehensive understanding.
Conflict resolution and prioritization#
When multiple sources are stitched together, contradictions surface. Documentation may describe an approach that a Slack thread quietly replaced months ago. When given access, agents surface both and leave reconciliation to the developer. Access without judgment only amplifies confusion.
A context engine resolves these conflicts by modeling recency, authority, and organizational patterns. It distinguishes between current practice and stale guidance, prioritizes decision relevant signals, and surfaces the context most likely to be correct for the decision at hand. This is what turns raw information into actionable context.
So what does this mean in practice?#
The industry has largely solved access. Agents can see more systems, more files, more history. What remains unsolved is understanding. Without an infrastructure layer that determines what context is relevant, authoritative, and safe for a specific developer in a specific moment, tools optimize for speed and plausibility, not correctness.
That gap is the real context problem. It is not about connecting more systems. It is about turning scattered organizational knowledge into decision grade context. Until that layer exists, “context aware” will continue to mean faster answers that still miss the point.
A few questions that come up#
What is a context engine?
A context engine is an infrastructure layer that continuously synthesizes organizational knowledge across code, PRs, tickets, chat, and docs into unified, conflict-resolved understanding — delivering decision-grade context to a specific developer or agent at a specific moment.
What’s the difference between a context engine and RAG?
RAG retrieves text chunks that look relevant and leaves judgment to the agent. A context engine synthesizes understanding across sources, resolves contradictions by recency and authority, and ranks results server-side before the agent acts. Retrieval returns fragments; a context engine returns decisions.
Why aren’t context-aware AI coding tools actually context-aware?
Most context-aware tools only expand access — more files, MCP servers, and larger context windows. They surface information but leave discernment to the agent, which stops at the first plausible answer. Access is not understanding.
What is satisfaction of search?
Satisfaction of search is the tendency of AI agents to stop exploring once they retrieve a plausible-looking answer, rather than confirming it aligns with intent, constraints, and prior decisions. It’s why adding more data sources doesn’t improve correctness.
Does adding more MCP servers make agents smarter?
No. More MCP servers increase access to information, not judgment. Each new source adds more to reconcile, and agents settle on the first plausible result — so quality can actually get worse as you wire in more sources.